本文发布已超过一年。较旧的文章可能包含过时的内容。请检查页面中的信息自发布以来是否已不正确。
引入 PodTopologySpread
在集群中管理 Pod 的分布是很困难的。众所周知的 Kubernetes Pod 亲和性和反亲和性功能允许在不同的拓扑结构中对 Pod 的放置进行一些控制。然而,这些功能只解决了一部分 Pod 分布用例:要么将无限数量的 Pod 放置到单个拓扑结构中,要么不允许两个 Pod 位于同一拓扑结构中。在这两种极端情况之间,通常需要将 Pod 均匀地分布在各个拓扑结构中,以便实现更好的集群利用率和应用程序的高可用性。
PodTopologySpread 调度插件(最初提议为 EvenPodsSpread)旨在填补这一空白。我们在 1.18 中将其提升为 beta 版。
API 更改
在 Pod 的 spec API 中引入了一个新的字段 topologySpreadConstraints
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
由于此 API 嵌入在 Pod 的 spec 中,因此您可以在所有高级工作负载 API(例如 Deployment、DaemonSet、StatefulSet 等)中使用此功能。
让我们看一个集群的示例来理解这个 API。
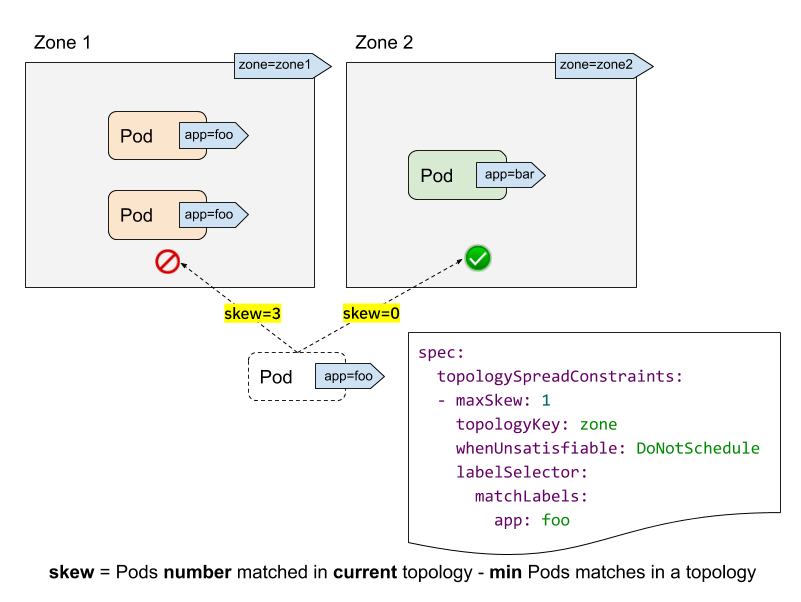
- labelSelector 用于查找匹配的 Pod。对于每个拓扑结构,我们计算与此标签选择器匹配的 Pod 的数量。在上面的示例中,给定标签选择器为“app: foo”,则“zone1”中的匹配数为 2;而“zone2”中的匹配数为 0。
- topologyKey 是定义节点标签中拓扑结构的键。在上面的示例中,一些节点被分组到“zone1”中(如果它们具有标签“zone=zone1”标签);而其他节点被分组到“zone2”中。
- maxSkew 描述了 Pod 分布不均匀的最大程度。在上面的示例中
- 如果我们把传入的 Pod 放到“zone1”,则“zone1”上的偏差将变为 3(“zone1”中匹配了 3 个 Pod;“zone2”上匹配的全局最小值为 0 个 Pod),这违反了“maxSkew: 1”约束。
- 如果将传入的 Pod 放置到“zone2”,则“zone2”上的偏差为 0(“zone2”中匹配了 1 个 Pod;“zone2”本身上匹配的全局最小值为 1 个 Pod),这满足了“maxSkew: 1”约束。请注意,偏差是根据每个合格的节点计算的,而不是全局偏差。
- whenUnsatisfiable 指定,当无法满足“maxSkew”时,应采取什么操作
DoNotSchedule(默认)告诉调度器不要调度它。这是一个硬约束。ScheduleAnyway告诉调度器仍然调度它,同时优先考虑减少偏差的节点。这是一个软约束。
高级用法
顾名思义,该功能的基本用法是以绝对均匀的方式(maxSkew=1)或相对均匀的方式(maxSkew>=2)运行您的工作负载。有关更多详细信息,请参阅官方文档。
除了这种基本用法外,还有一些高级用法示例,可使您的工作负载受益于高可用性和集群利用率。
与 NodeSelector / NodeAffinity 一起使用
您可能已经发现,我们没有“topologyValues”字段来限制 Pod 将被调度到的拓扑结构。默认情况下,它将搜索所有节点并按“topologyKey”对它们进行分组。有时,这可能不是理想的情况。例如,假设有一个集群,其节点标记为“env=prod”、“env=staging”和“env=qa”,现在您想将 Pod 均匀地放置到跨区域的“qa”环境中,这可能吗?
答案是肯定的。您可以利用 NodeSelector 或 NodeAffinity API 规范。在底层,PodTopologySpread 功能将遵守该规范,并计算满足选择器的节点之间的分布约束。
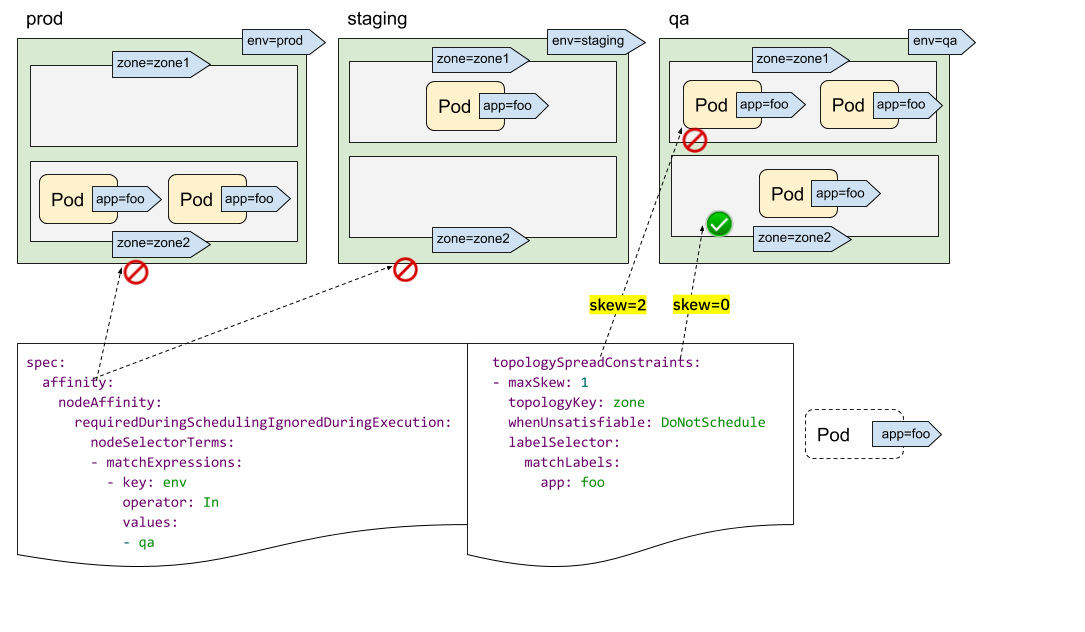
如上图所示,您可以指定 spec.affinity.nodeAffinity 将“搜索范围”限制为“qa”环境,并且在该范围内,Pod 将被调度到满足 topologySpreadConstraints 的区域。在这种情况下,它是“zone2”。
多个 TopologySpreadConstraints
理解单个 TopologySpreadConstraint 的工作原理是很直观的。那么,多个 TopologySpreadConstraints 的情况如何?在内部,每个 TopologySpreadConstraint 都是独立计算的,并且结果集将被合并以生成最终结果集——即,合适的节点。
在以下示例中,我们希望同时将 Pod 调度到具有 2 个要求的集群
- 将 Pod 与各个区域的 Pod 均匀放置
- 将 Pod 与各个节点的 Pod 均匀放置
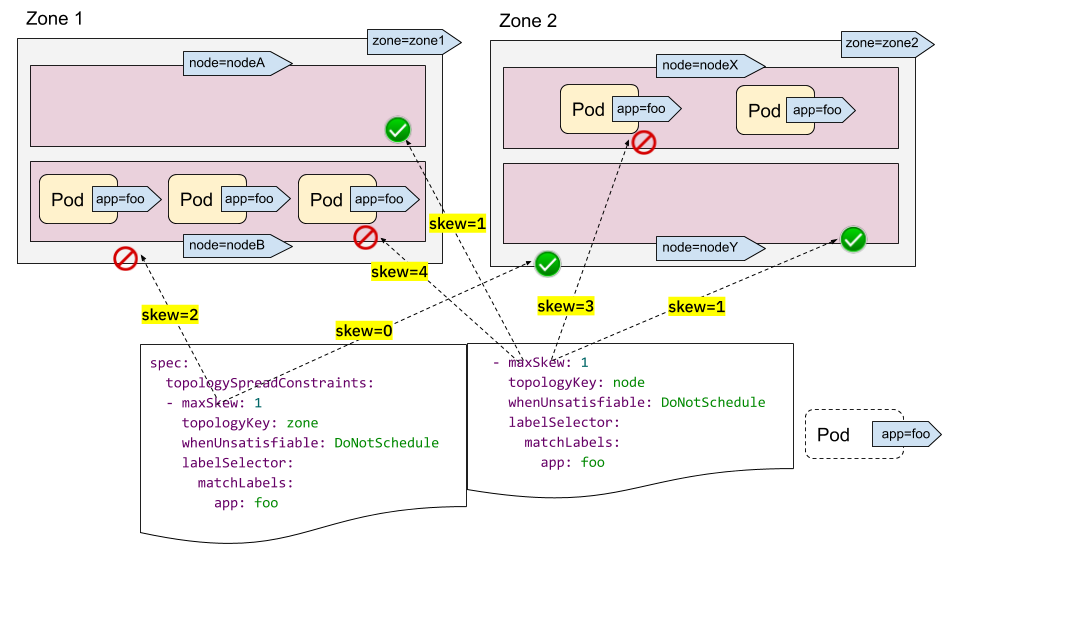
对于第一个约束,zone1 中有 3 个 Pod,zone2 中有 2 个 Pod,因此传入的 Pod 只能放置到 zone2 中以满足“maxSkew=1”约束。换句话说,结果集是 nodeX 和 nodeY。
对于第二个约束,nodeB 和 nodeX 中有太多 Pod,因此传入的 Pod 只能放置到 nodeA 和 nodeY 中。
现在我们可以得出结论,唯一合格的节点是 nodeY - 来自集合 {nodeX, nodeY}(来自第一个约束)和 {nodeA, nodeY}(来自第二个约束)的交集。
多个 TopologySpreadConstraints 功能强大,但请务必了解它与前面“NodeSelector/NodeAffinity”示例的区别:一个是独立计算结果集然后进行连接;而另一个是基于节点约束的过滤结果计算 topologySpreadConstraints。
您可以组合使用“硬”约束和“软”约束,而不是在所有 topologySpreadConstraints 中都使用“硬”约束,以适应更多样化的集群情况。
注意
如果两个 TopologySpreadConstraints 应用于相同的 {topologyKey, whenUnsatisfiable} 元组,则 Pod 创建将被阻止并返回验证错误。PodTopologySpread 默认值
PodTopologySpread 是 Pod 级别的 API。因此,要使用该功能,工作负载作者需要了解集群的底层拓扑,然后在每个工作负载的 Pod 规范中指定适当的 topologySpreadConstraints。虽然 Pod 级别 API 提供了最大的灵活性,但也可以指定集群级别的默认值。
默认的 PodTopologySpread 约束允许您为集群中的所有工作负载指定分布,并针对其拓扑结构进行定制。当启动 kube-scheduler 时,运算符/管理员可以在调度配置文件配置 API 中将约束指定为 PodTopologySpread 插件参数。
一个示例配置可能如下所示
apiVersion: kubescheduler.config.k8s.io/v1alpha2
kind: KubeSchedulerConfiguration
profiles:
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: example.com/rack
whenUnsatisfiable: ScheduleAnyway
配置默认约束时,标签选择器必须留空。kube-scheduler 将从 Pod 到服务、ReplicationControllers、ReplicaSets 或 StatefulSets 的成员关系中推断标签选择器。Pod 始终可以通过 PodSpec 提供自己的约束来覆盖默认约束。
注意
当使用默认的 PodTopologySpread 约束时,建议禁用旧的 DefaultTopologySpread 插件。总结
PodTopologySpread 允许您使用灵活且富有表现力的 Pod 级别 API 为您的工作负载定义分布约束。过去,工作负载作者使用 Pod 反亲和性规则来强制或提示调度程序在每个拓扑域中运行单个 Pod。相反,新的 PodTopologySpread 约束允许 Pod 指定可以要求(硬)或期望(软)的偏差级别。该功能可以与节点选择器和节点亲和性配对,以将分布限制到特定域。可以为不同的拓扑结构(例如主机名、区域、区域、机架等)定义 Pod 分布约束。
最后,集群操作员可以定义要应用于所有 Pod 的默认约束。这样,Pod 不需要了解集群的底层拓扑。